JVM垃圾回收与算法
个人博客
JVM垃圾回收与算法
前言
本文为学习Java相关知识所作笔记,参考以下资料:https://github.com/Snailclimb/JavaGuide ,感谢原作者的分享!
垃圾回收与算法
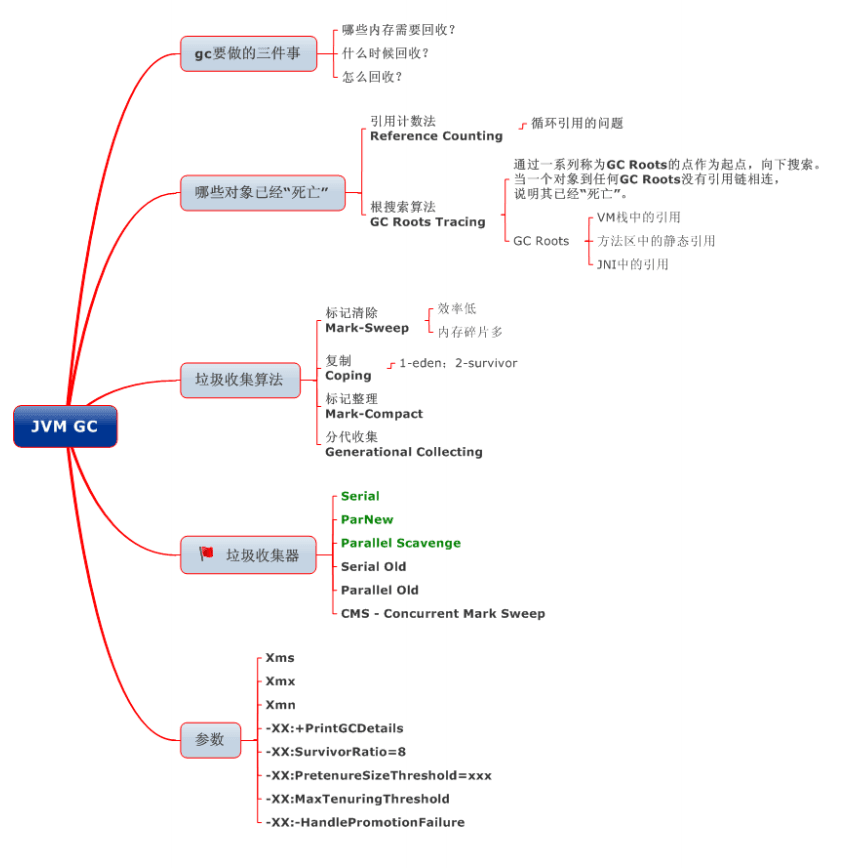
如何确定垃圾
引用计数法
在 Java 中,引用和对象是有关联的。如果要操作对象则必须用引用进行。因此,很显然一个简单的办法是通过引用计数来判断一个对象是否可以回收。简单说,即一个对象如果没有任何与之关联的引用,即他们的引用计数都不为 0,则说明对象不太可能再被用到,那么这个对象就是可回收对象。
可达性分析
为了解决引用计数法的循环引用问题,Java 使用了可达性分析的方法。通过一系列的“GC roots”对象作为起点搜索。如果在“GC roots”和一个对象之间没有可达路径,则称该对象是不可达的。要注意的是,不可达对象不等价于可回收对象,不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
标记清除算法(Mark-Sweep)
最基础的垃圾回收算法,分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。如图
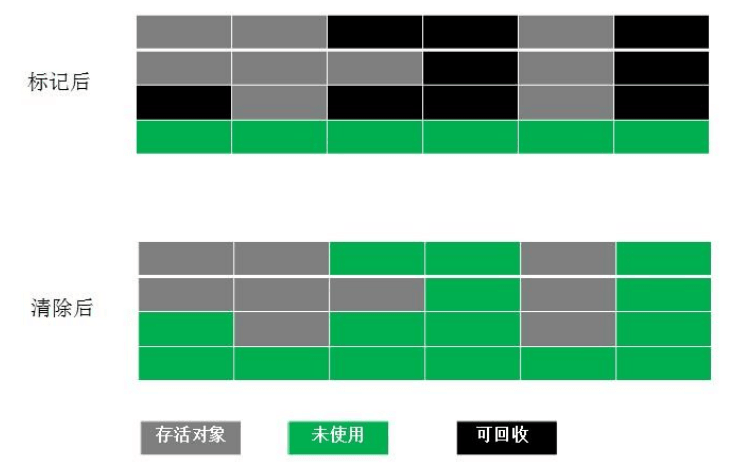
从图中我们就可以发现,该算法最大的问题是内存碎片化严重,后续可能发生大对象不能找到可利用空间的问题。
复制算法(copying)
为了解决 Mark-Sweep 算法内存碎片化的缺陷而被提出的算法。按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉,如图:
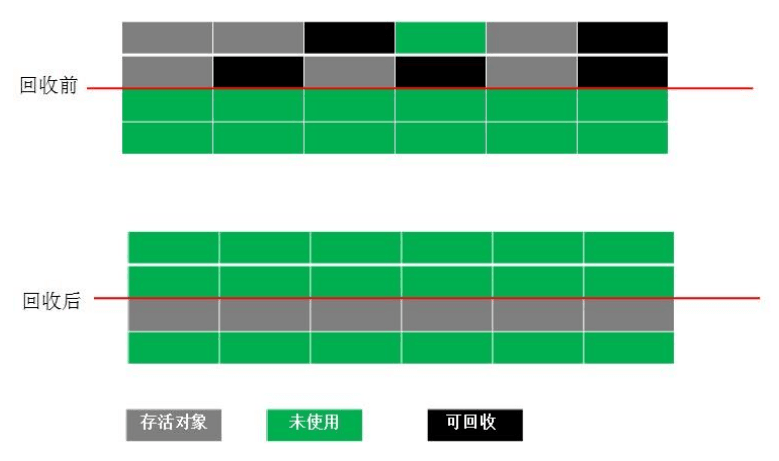
这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是可用内存被压缩到了原本的一半。且存活对象增多的话,Copying 算法的效率会大大降低。
标记整理算法(Mark-Compact)
结合了以上两个算法,为了避免缺陷而提出。标记阶段和 Mark-Sweep 算法相同,标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。如图:

分代收集算法
分代收集法是目前大部分 JVM 所采用的方法,其核心思想是根据对象存活的不同生命周期将内存划分为不同的域,一般情况下将 GC 堆划分为老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特点是每次垃圾回收时只有少量对象需要被回收,新生代的特点是每次垃圾回收时都有大量垃圾需要被回收,因此可以根据不同区域选择不同的算法。
新生代与复制算法
目前大部分 JVM 的 GC 对于新生代都采取 Copying 算法,因为新生代中每次垃圾回收都要回收大部分对象,即要复制的操作比较少,但通常并不是按照 1:1 来划分新生代。一般将新生代划分为一块较大的 Eden 空间和两个较小的 Survivor 空间(From Space, To Space),每次使用Eden 空间和其中的一块 Survivor 空间,当进行回收时,将该两块空间中还存活的对象复制到另一块 Survivor 空间中
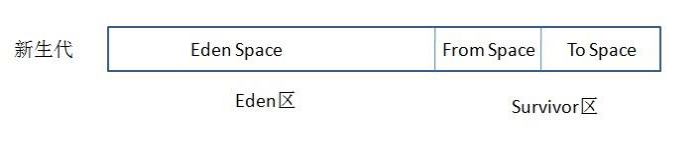
老年代与标记复制算法
而老年代因为每次只回收少量对象,因而采用 Mark-Compact 算法。
JAVA 虚拟机提到过的处于方法区的永生代(Permanet Generation),它用来存储 class 类,常量,方法描述等。对永生代的回收主要包括废弃常量和无用的类。
对象的内存分配主要在新生代的 Eden Space 和 Survivor Space 的 From Space(Survivor 目前存放对象的那一块),少数情况会直接分配到老生代。
当新生代的 Eden Space 和 From Space 空间不足时就会发生一次 GC,进行 GC 后,Eden Space 和 From Space 区的存活对象会被挪到 To Space,然后将 Eden Space 和 From Space 进行清理。
如果 To Space 无法足够存储某个对象,则将这个对象存储到老生代。
在进行 GC 后,使用的便是 Eden Space 和 To Space 了,如此反复循环。
当对象在 Survivor 区躲过一次 GC 后,其年龄就会+1。默认情况下年龄到达 15 的对象会被移到老生代中。
JAVA 四中引用类型
强引用
在 Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它处于可达状态,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到 JVM 也不会回收。因此强引用是造成 Java 内存泄漏的主要原因之一。
软引用
软引用需要用 SoftReference 类来实现,对于只有软引用的对象来说,当系统内存足够时它不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中。
弱引用
弱引用需要用 WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存。
虚引用
虚引用需要 PhantomReference 类来实现,它不能单独使用,必须和引用队列联合使用。虚引用的主要作用是跟踪对象被垃圾回收的状态
GC 分代收集算法 VS 分区收集算法
分代收集算法
当前主流 VM 垃圾收集都采用”分代收集”(Generational Collection)算法, 这种算法会根据对象存活周期的不同将内存划分为几块, 如 JVM 中的 新生代、老年代、永久代,这样就可以根据各年代特点分别采用最适当的 GC 算法
在新生代-复制算法
每次垃圾收集都能发现大批对象已死, 只有少量存活. 因此选用复制算法, 只需要付出少量存活对象的复制成本就可以完成收集.
在老年代-标记整理算法
因为对象存活率高、没有额外空间对它进行分配担保, 就必须采用“标记—清理”或“标记—整理”算法来进行回收, 不必进行内存复制, 且直接腾出空闲内存.
分区收集算法
分区算法则将整个堆空间划分为连续的不同小区间, 每个小区间独立使用, 独立回收. 这样做的好处是可以控制一次回收多少个小区间 , 根据目标停顿时间, 每次合理地回收若干个小区间(而不是整个堆), 从而减少一次 GC 所产生的停顿
GC 垃圾收集器
Java 堆内存被划分为新生代和年老代两部分,新生代主要使用复制和标记-清除垃圾回收算法;年老代主要使用标记-整理垃圾回收算法,因此 java 虚拟中针对新生代和年老代分别提供了多种不同的垃圾收集器,JDK1.6 中 Sun HotSpot 虚拟机的垃圾收集器如下:
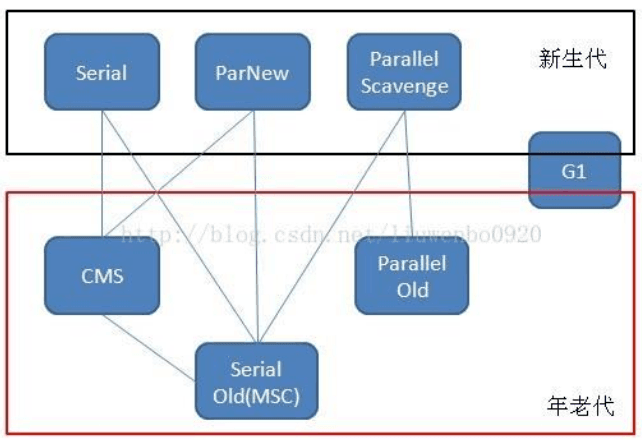
Serial 垃圾收集器(单线程、复制算法)
Serial(英文连续)是最基本垃圾收集器,使用复制算法,曾经是JDK1.3.1 之前新生代唯一的垃圾收集器。Serial 是一个单线程的收集器,它不但只会使用一个 CPU 或一条线程去完成垃圾收集工作,并且在进行垃圾收集的同时,必须暂停其他所有的工作线程,直到垃圾收集结束。Serial 垃圾收集器虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限定单个 CPU 环境来说,没有线程交互的开销,可以获得最高的单线程垃圾收集效率,因此 Serial垃圾收集器依然是 java 虚拟机运行在 Client 模式下默认的新生代垃圾收集器
ParNew 垃圾收集器(Serial+多线程)
ParNew 垃圾收集器其实是 Serial 收集器的多线程版本,也使用复制算法,除了使用多线程进行垃圾收集之外,其余的行为和 Serial 收集器完全一样,ParNew 垃圾收集器在垃圾收集过程中同样也要暂停所有其他的工作线程
ParNew 收集器默认开启和 CPU 数目相同的线程数,可以通过-XX:ParallelGCThreads 参数来限制垃圾收集器的线程数。【Parallel:平行的】ParNew虽然是除了多线程外和Serial 收集器几乎完全一样,但是ParNew垃圾收集器是很多 java虚拟机运行在 Server 模式下新生代的默认垃圾收集器
Parallel Scavenge 收集器(多线程复制算法、高效)
Parallel Scavenge 收集器也是一个新生代垃圾收集器,同样使用复制算法,也是一个多线程的垃圾收集器,它重点关注的是程序达到一个可控制的吞吐量(Thoughput,CPU 用于运行用户代码的时间/CPU 总消耗时间,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)),高吞吐量可以最高效率地利用 CPU 时间,尽快地完成程序的运算任务,主要适用于在后台运算而不需要太多交互的任务。自适应调节策略也是 ParallelScavenge 收集器与 ParNew 收集器的一个重要区别。
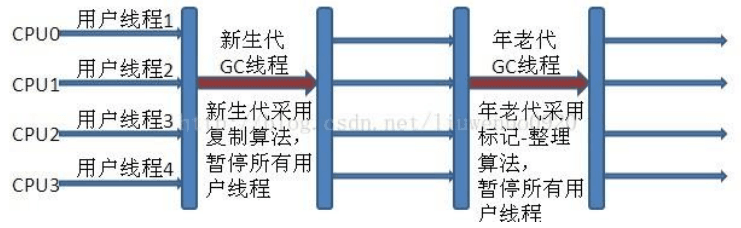
Serial Old 收集器(单线程标记整理算法 )
Serial Old 是 Serial 垃圾收集器年老代版本,它同样是个单线程的收集器,使用标记-整理算法,这个收集器也主要是运行在 Client 默认的 java 虚拟机默认的年老代垃圾收集器。 在 Server 模式下,主要有两个用途:
- 在 JDK1.5 之前版本中与新生代的 Parallel Scavenge 收集器搭配使用。
- 作为年老代中使用 CMS 收集器的后备垃圾收集方案。
新生代 Serial 与年老代 Serial Old 搭配垃圾收集过程图
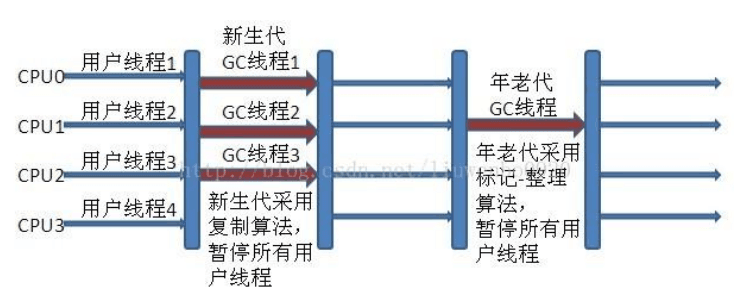
新生代 Parallel Scavenge 收集器与 ParNew 收集器工作原理类似,都是多线程的收集器,都使用的是复制算法,在垃圾收集过程中都需要暂停所有的工作线程。新生代 Parallel Scavenge/ParNew 与年老代 Serial Old 搭配垃圾收集过程图:
Parallel Old 收集器(多线程标记整理算法)
Parallel Old 收集器是Parallel Scavenge的年老代版本,使用多线程的标记-整理算法,在 JDK1.6才开始提供。
在 JDK1.6 之前,新生代使用 ParallelScavenge 收集器只能搭配年老代的 Serial Old 收集器,只能保证新生代的吞吐量优先,无法保证整体的吞吐量,Parallel Old 正是为了在年老代同样提供吞吐量优先的垃圾收集器,如果系统对吞吐量要求比较高,可以优先考虑新生代 Parallel Scavenge和年老代 Parallel Old 收集器的搭配策略。新生代 Parallel Scavenge 和年老代 Parallel Old 收集器搭配运行过程图:
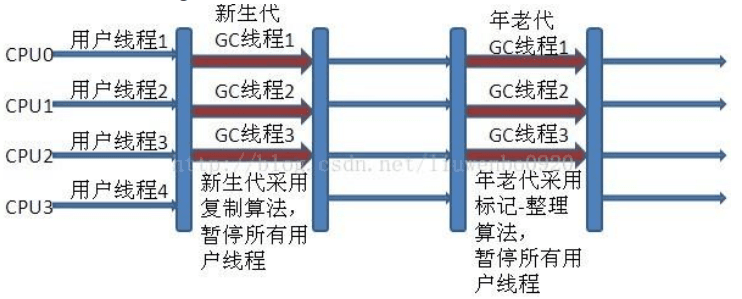
CMS 收集器(多线程标记清除算法)
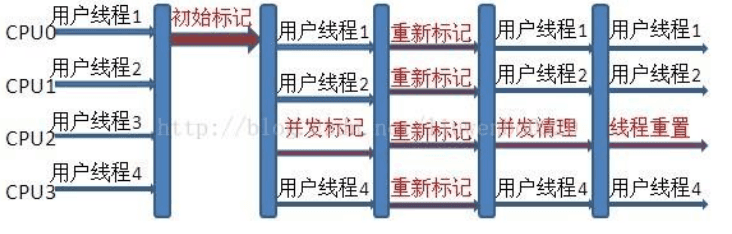
Concurrent mark sweep(CMS)收集器是一种年老代垃圾收集器,其最主要目标是获取最短垃圾回收停顿时间,和其他年老代使用标记-整理算法不同,它使用多线程的标记-清除算法。最短的垃圾收集停顿时间可以为交互比较高的程序提高用户体验。CMS 工作机制相比其他的垃圾收集器来说更复杂,整个过程分为以下 4 个阶段:
初始标记
只是标记一下 GC Roots 能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
并发标记
进行 GC Roots 跟踪的过程,和用户线程一起工作,不需要暂停工作线程。
重新标记
为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。
并发清除
清除 GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程。由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看CMS 收集器的内存回收和用户线程是一起并发地执行。
CMS 收集器工作过程:
G1 收集器
Garbage first 垃圾收集器是目前垃圾收集器理论发展的最前沿成果,相比与 CMS 收集器,G1 收集器两个最突出的改进是:
- 基于标记-整理算法,不产生内存碎片。
- 可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。
G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,并且跟踪这些区域的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾最多的区域。区域划分和优先级区域回收机制,确保 G1 收集器可以在有限时间获得最高的垃圾收集效率